Une nouvelle ère pour le Supply Chain Management
Sous l’impulsion de la recherche universitaire et de grandes entreprises comme Walmart ou Procter & Gamble, le secteur de la logistique a subi une première transformation importante dans les années 1990. Tandis que certains acteurs sont encore attelés à la mise en œuvre des meilleures pratiques, le Big Data est aujourd’hui en train de révolutionner à nouveau la chaîne d’approvisionnement.
Sous l’appellation « Supply Chain 4.0 » ou « Supply Chain connectée », ces avancées prometteuses sont le fait d’équipes de Data Scientists exploitant l’intelligence artificielle, la blockchain ou encore la robotique. Ces technologies visent à rendre la chaîne logistique plus agile, prévisible et rentable pour les organisations. Comment ? En raccourcissant les délais d’approvisionnement, en automatisant totalement la prévision de la demande, ou encore en améliorant la ponctualité en matière de production et de livraison.
Les apports de la Data Science au secteur de la Supply Chain
Mieux anticiper la demande
Capables d’exploiter des sources d’informations très larges et diversifiées, la Data Science et le Machine Learning sont particulièrement intéressants pour dégager des tendances dans une très grande quantité de données.
Dans le secteur de la Supply Chain, la Data Science sert en particulier à :
- identifier des signaux faibles à surveiller de façon active pour élaborer des choix prospectifs ;
- intégrer des données depuis différentes sources (web…) ;
- grouper les produits selon différents comportements de consommation ;
- mettre en évidence des stratégies d’action adaptées à chaque situation.
Optimiser la gestion des flux logistiques
En matière de gestion des stocks, l’analyse de données peut être mise en corrélation avec certains facteurs externes (problèmes d’approvisionnement en matières premières, trafic des marchandises, conditions météorologiques…) pour aider les entreprises à réduire les risques de rupture.
Pour faciliter le choix des transporteurs et optimiser l’organisation des tournées de livraison, de nombreux facteurs peuvent ainsi être pris en compte : coûts, type de produits à prendre en charge, normes et conditions spécifiques de transport, conditionnement, trafic routier…
En distribuant les tâches de manière optimale en fonction des données propres de l’entrepôt, les algorithmes de l’IA contribuent également à une meilleure allocation des ressources et permettent ainsi d’obtenir de meilleurs rendements.
Améliorer la relation client
Avec la Data Science, la relation établie avec les consommateurs devient aussi de plus en plus personnalisée. Les algorithmes de Machine Learning non supervisés permettent en particulier de segmenter très finement la clientèle afin de pouvoir cibler au mieux les offres promotionnelles et services à proposer à chaque profil.
Combinées à l’analyse des retours clients, ces données de segmentation apportent de précieuses informations sur les démarches à engager pour améliorer la satisfaction client qui demeure au cœur des préoccupations de toute chaîne logistique.
Sur le même sujet : Relation client : évolutions et bonnes pratiques
La collaboration homme/machine : un enjeu primordial pour la Data Science
De la donnée à l’action
Dans tout processus d’intelligence artificielle, l’autonomie donnée à la machine s’effectue progressivement. Ce schéma du cabinet Gartner montre bien comment le travail confié aux systèmes (en bleu) vient petit à petit remplacer les interventions humaines (matérialisées en vert).
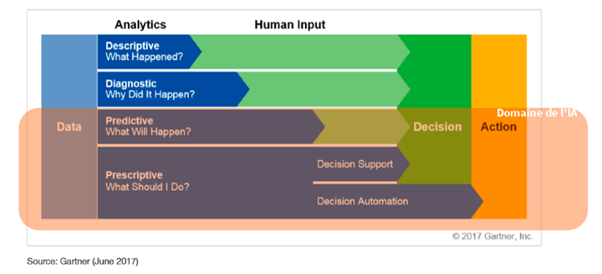
La collaboration entre l’homme et la machine se déroule alors en 4 grandes étapes :
- l’analyse des données par la machine (Analytics) ;
- l’intervention humaine nécessaire à l’interprétation des données (Human input) ;
- la prise de décision qui en découle (Decision) ;
- la transformation en action concrète (Action).
Au fil du temps, la part d’autonomie laissée à la machine est de plus en plus grande, jusqu’à ce qu’on l’on puisse obtenir une confiance totale dans le système. Mais pour rendre la machine capable de décider aussi bien que l’homme, une phase de collaboration est indispensable durant les différentes étapes d’élaboration de l’algorithme. Elle est plus ou moins longue et poussée selon le degré d’autonomie souhaité.
Les différents types d’algorithmes
Selon la nature et la profondeur de la collaboration entre l’homme et la machine, on distingue trois grandes familles d’algorithmes de machine learning : il est ici question d’apprentissage en mode supervisé, non supervisé ou par renforcement.
L’apprentissage supervisé
En mode supervisé, les algorithmes fonctionnent à partir de données choisies par l’homme pour leurs caractéristiques et leur impact connu sur le résultat. Par exemple : la courbe des températures extérieures influence les ventes de boissons, ou le nombre de commandes à expédier impacte la charge de picking en entrepôt. Les modèles de prévisions des ventes utilisent ce type d’algorithme en particulier.
L’intelligence est dans ce cas principalement apportée par l’homme. La machine est alors essentiellement utilisée pour ses capacités de calcul sur la base de plusieurs séries de données.
L’apprentissage non supervisé
Il s’agit ici de répondre à 2 objectifs particuliers :
- créer des clusters, c’est-à-dire des groupes d’individus aux comportements similaires, afin de définir des règles de gestion affinées et donc particulièrement performantes ;
- découvrir grâce à la machine quelles données ont un impact sur les performances de la chaîne logistique : l’approche théorique acquise en tant que professionnel ne suffit pas toujours à détecter et expliquer certains phénomènes pouvant affecter l’efficacité d’un entrepôt. Capable d’identifier même des signaux faibles, en temps réel et en continu, la machine représente alors un puissant vecteur d’analyse des opérations, et donc d’amélioration des processus.
Dans les deux cas, la machine sert à établir le diagnostic, tandis que l’homme intervient dans l’exploitation des données et la définition des actions à entreprendre en conséquence.
L’apprentissage par renforcement
Principalement utilisés par les assistants vocaux ou bancaires et la robotique, ces algorithmes fonctionnent sur des cycles d’expérience, et améliorent leurs performances à chaque itération. C’est le mode de collaboration le plus poussé entre l’homme et la machine. Par un principe de scoring, l’humain apprend progressivement au système à prendre les meilleures décisions. Il lui transfère ainsi son expérience et lui apprend à s’adapter face à de nombreux cas de figure.